贡献#
如果您正在阅读本节,您可能对贡献 JupyterLab 感兴趣。欢迎并感谢您有兴趣贡献!
请查阅贡献者文档,熟悉 JupyterLab 的使用,并在社区(通过聊天和/或论坛)中介绍自己,分享您感兴趣的项目领域。另请参阅 Jupyter 社区指南。
您可以通过以下方式使其变得更好:
我们将一些问题标记为适合初学者的问题或需要帮助,我们认为这些是小型、独立更改的良好示例。我们鼓励对代码库不熟悉的人实现和/或询问有关这些问题的问题。您无需请求许可即可处理此类问题,但如果您请求并在 48 小时内未收到回复,请假定没有其他人正在处理(即使之前有人自愿),并打开一个带有提议实现的拉取请求。如果您不确定实现,建议使用草稿拉取请求。
如果您认为在 JupyterLab 或任何 Jupyter 项目中发现了安全漏洞,请报告给 security@ipython.org。如果您希望加密您的安全报告,可以使用此 PGP 公钥。
贡献通用指南#
有关贡献 Jupyter 项目的通用文档,请参阅 Jupyter 项目贡献者文档和行为准则。
向后兼容性、版本和重大变更#
新版本的 JupyterLab 可能会破坏与扩展和其他 Jupyter 自定义功能的向后兼容性。重大变更尽可能地保持在最低限度。JupyterLab 的开发和发布周期遵循语义版本控制,因此当需要进行重大变更时,它们会通过版本编号方案进行传达。简而言之,这意味着对于 JupyterLab 版本 X.Y.Z:
主版本号 (X) 更改表示重大变更(不向后兼容)
次版本号 (Y) 更改表示向后兼容的新功能添加
补丁版本号 (Z) 更改表示向后兼容的 bug 修复
对 JupyterLab 扩展和其他自定义功能的贡献应考虑可能出现的重大变更。请考虑在这些项目中向用户记录您的维护计划。您可能还希望在开发扩展时(在您的包元数据中)考虑固定 JupyterLab 的主版本。
我们会在 JupyterLab 的继任者首次发布后一年内维护其主要版本。详情请参阅版本生命周期。JupyterLab v4 于 2023 年 5 月 15 日发布,因此 JupyterLab v3 将维护至 2024 年 5 月 15 日。JupyterLab v1 和 v2 已不再维护。强烈建议所有 JupyterLab v2 和 v3 用户尽快升级。
语言、工具和流程#
所有源代码均使用 TypeScript 编写。请参阅样式指南。
所有非 Python 源代码都使用 prettier 格式化,Python 源代码使用 ruff 格式化。当代码被修改并提交时,所有暂存的文件都将使用预提交 git 钩子(在 pre-commit 的帮助下)自动格式化。prettier 和 ruff 等代码格式化程序的好处是,在审查拉取请求时,它们消除了代码样式的话题,从而加快了审查过程。
只要您的代码有效,pre-commit 钩子应该会处理其外观。pre-commit 及其相关钩子将在您运行 pip install -e ".[dev,test]" 时自动安装。
要手动安装 pre-commit,请运行以下命令:
pip install pre-commit
pre-commit install
您可以随时手动调用 pre-commit 钩子:
pre-commit run
这应该会运行您的代码的任何自动格式化,并告诉您任何无法自动修复的错误。您也可以将 ruff 集成安装到您的文本编辑器中,以自动格式化代码。
如果您在通过 pre-commit install 设置 pre-commit 钩子之前已经提交了文件,您可以使用 pre-commit run --all-files 来修复所有问题。之后您需要自己进行修复提交。
您也可以使用 prettier npm 脚本(例如 npm run prettier 或 yarn prettier 或 jlpm prettier)来格式化整个代码库。我们建议为您的代码编辑器安装 prettier 扩展,并将其配置为通过键盘快捷键或在保存时自动格式化您的代码。
提交拉取请求贡献#
通常,在打开拉取请求之前,应先打开一个问题,描述一项拟议的工作及其解决的问题。审查员将确保您的问题符合我们“准备就绪”的定义,然后我们才能合并任何与该问题相关的拉取请求。
拉取请求必须指向开发分支(= main),即使其目的是解决稳定版本中出现的问题。一旦拉取请求合并到开发分支,它将使用机器人操作(如果机器人操作失败,则手动)回溯到稳定分支。
注意
请务必在 PR 描述中提及目标版本。维护者将相应地设置里程碑。
问题管理#
提出问题可以让社区成员参与设计讨论,让其他人了解正在进行的工作,并为富有成效的社区互动奠定基础。当您提出新的错误或增强请求时,请在问题模板中提供所有所需信息,以便响应者能够及时对您的错误进行分类。
拉取请求应引用其正在解决的问题。一旦拉取请求合并,与之相关的问题也将关闭。如果围绕实现有额外的讨论,问题可能会重新打开。一旦 30 天过去而没有额外的讨论,锁定机器人将锁定问题。如果需要额外的讨论,或者拉取请求未能完全解决锁定的问题,请打开一个新问题,引用锁定的问题。
新问题需进行分类。具有分类权限的开发者(分类员)将执行以下操作:
阅读问题
搜索现有问题并在必要时将其标记为重复
如果需要额外信息,添加评论请求
如果问题已准备好处理,将其分配给一个里程碑
为问题应用适当的标签(请参阅下面的示例)
开发者可以在问题提出后立即开始处理。如果他们对您的问题有任何疑问,请与分类员合作,以便您的更改可以及时合并。
准备就绪的定义#
分类的主要目标之一是使问题处于准备就绪的状态,以便有人可以处理。一旦分类员确认问题符合以下定义,他们将从其中删除 status:Needs Triage 标签。我们不会合并仍在等待分类的问题的拉取请求。
分类员还应确保问题具有描述它的适当标签,例如带有 pkg: 前缀的标签,用于影响一个或多个包的问题。
所有请求的信息(在适用情况下)均已提供。来自 JupyterLab 问题模板:
对于bug
描述,最好包含截图
重现步骤
预期行为
上下文,例如操作系统、浏览器、JupyterLab 版本以及输出或日志摘录
对于功能请求
问题描述
拟议解决方案的描述
额外上下文
该问题应代表真实、相关、可行的工作。简而言之,如果将此问题分配给一位知识渊博的人员,他们将能够以合理的努力和协助完成它,并且它能推动 Jupyter 项目的目标。
问题应该是唯一的;分类是识别重复问题的最佳时机。
错误代表了使用 Jupyter 产品和服务的有效期望。
对安全性、性能、可访问性和本地化的期望应符合使用 Jupyter 产品的社区中普遍接受的规范。
问题代表了一位开发者可以负责的工作,即使他们与其他开发者协作以获取反馈。过大的问题应拆分为多个问题,每个问题单独分类,或拆分为团队指南问题,以讨论更实质性的更改。
分类员使用的标签#
所有新错误和增强请求都带有 status:Needs Triage 标签。
Jupyter 贡献者(分类审核员或分类员)定期审查标记为 status:Needs Triage 的 JupyterLab 问题,从最旧的开始,并确定它们是否符合“准备就绪”的定义。
一旦分类完毕,如果问题已准备就绪,审查员将删除 status:Needs Triage 标签;不需要额外的标签。如果问题中没有足够的信息,分类审查员会应用 status:Needs Info 标签并保留 status:Needs Triage。如果问题在 status:Needs Info 状态下保持超过 14 天而没有任何后续沟通,审查员应应用 status:Blocked。如果问题在另外 14 天内没有收到解除阻塞的回复,则应关闭此阻塞问题。
我们期望每个新问题都在创建后一周内得到审查。
分类员应将较简单/复杂度较低的问题标记为 good first issue,以方便初学者贡献。一个好的初次问题应具备:
清晰易懂的描述,包含截图和预期,无需对项目有太多熟悉度
描述中或评论中包含与问题相关的文档和源代码文件的链接
建议的联系方式,可以是 GitHub 用户名或在其他论坛(Discourse 等)上,贡献者可以在那里获得帮助
除非问题具有时间敏感性,例如即将发布的版本阻碍,否则经验丰富的 Jupyter 贡献者应避免处理带有 good first issue 标签的近期问题。
使用标签标记问题#
没有 JupyterLab 仓库提交权限的用户可以使用 @meeseeksdev 机器人为问题添加标签。例如:要为一个问题应用标签 foo 和 bar baz,请在该问题上评论 @meeseeksdev tag foo "bar baz"。
从浏览器内贡献#
无需设置本地环境,直接从网络浏览器也可以向 JupyterLab 代码库贡献:
GitHub 的内置编辑器适用于贡献非常小的修复,
通过在 JupyterLab GitHub 仓库中按下句点 (
.) 键,可以访问更高级的 github.dev 编辑器,Gitpod 集成已启用,但目前并未积极维护,
jupyterlab-playground 允许在 JupyterLab 内原型化 JupyterLab 扩展,并且可以使用 Binder 在浏览器中无需安装即可运行。
使用 Binder,您也可以在浏览器中测试当前的 main 分支和您的更改。我们建议您至少有 8 GB 的 RAM。要构建并启动最新 JupyterLab main 的实例,请在新标签页中打开此链接。构建大约需要 7 分钟才能完成。
要测试您在 GitHub 上托管的自己的分支,请在 https://mybinder.org 上输入。如果一切顺利,填写表单大约需要 2 分钟,构建大约需要 7 分钟。
设置本地开发环境#
注意
请参阅自动化开发环境部分,了解一些设置本地开发环境的自动化方法。
本节解释如何设置本地开发环境。我们假设您使用 GNU/Linux、macOS 或适用于 Linux 的 Windows 子系统。如果使用 Windows,我们建议安装适用于 Windows 的 Anaconda,然后使用 Anaconda 命令行提示符执行所有安装步骤。
安装 Node.js 和 jlpm#
从其 GitHub 源代码构建 JupyterLab 需要 Node.js。开发版本需要 Node.js 20+ 版本,如 dev_mode/package.json 中的 engines 规范所定义。
如果您使用 conda,您可以通过以下方式获取它:
conda install -c conda-forge nodejs=20
如果您在 macOS 上使用 Homebrew:
brew install node
您也可以从 Node.js 网站下载安装程序。
要检查已安装的 Node.js 版本:
node -v
使用自动化设置本地开发环境#
虽然通过上述步骤可以学到很多东西,但它们可以自动化以节省时间。使用自动化的主要优点是:减少环境启动和运行所需的时间,减少重新构建环境所需的时间,更好的标准化(“基线”,可重现环境)。本节介绍如何使用 VS Code 开发容器、Docker 和 Vagrant 来实现这一点。
VS Code 设置#
要使用 VS Code 开发容器启动 JupyterLab 的本地开发环境,您需要:
git clone https://github.com/<your-github-username>/jupyterlab.git
使用 VS Code 打开本地克隆。
在容器中打开仓库。VS Code 应该会弹出一个窗口提示您这样做。如果未提示,您可以点击左下角的图标
><。然后选择在容器中重新打开。
注意
第一次会花费相当长的时间。
使用 Docker 进行设置#
要在安装了 docker 的 UNIX 系统中启动 JupyterLab 开发容器:
派生 JupyterLab 仓库。
启动容器
git clone https://github.com/<your-github-username>/jupyterlab.git
cd jupyterlab
bash docker/start.sh
上述命令将在 Docker 镜像不存在时构建它,然后启动容器,使 JupyterLab 在监视模式下运行。端口 8888 被暴露,当前的 JupyterLab 仓库被挂载到容器中。然后您可以使用您喜欢的 IDE 开始开发 JupyterLab,JupyterLab 将实时重建。
其他可用命令
bash docker/start.sh dev 4567 # Start JupyterLab dev container at port 4567
bash docker/start.sh stop # Stop the running container
bash docker/start.sh clean # Remove the docker image
bash docker/start.sh build # Rebuild the docker image
# Log into the container's shell with the JupyterLab environment activated.
# It's useful to run the tests or install dependencies.
bash docker/start.sh shell
要将 TypeScript 依赖项添加到项目中,您需要登录到容器的 shell,安装依赖项以更新 package.json 和 yarn.lock 文件,然后重建 docker 镜像。
bash docker/start.sh shell
# In the container shell
jlpm add ...
exit
# Back to host shell
bash docker/start.sh build
使用 Vagrant 进行设置#
一个实用的例子可以在这里找到,其中包括一个 Vagrantfile、引导文件和额外的文档。
安装 JupyterLab#
派生 JupyterLab 仓库。
然后使用以下步骤:
git clone https://github.com/<your-github-username>/jupyterlab.git
cd jupyterlab
pip install -e ".[dev,test]"
jlpm install
jlpm run build # Build the dev mode assets
# Build the core mode assets
jlpm run build:core
# Build the app dir assets
jupyter lab build
常见问题#
重要
在 Windows 上,对于 Python 3.8 或更高版本,需要通过激活“开发人员模式”来激活 Windows 10 或更高版本上的符号链接。您的管理员可能不允许这样做。有关说明,请参阅在 Windows 上激活开发人员模式。
一些脚本将运行“python”。如果您的目标 python 被称为其他名称(例如“python3”),那么构建的某些部分将会失败。您可能希望在 conda 环境中构建,或创建别名。
jlpm命令是 JupyterLab 提供的、锁定的 yarn 包管理器版本。如果您已经安装了yarn,您可以在开发时使用yarn命令,它将在仓库或构建的应用程序目录中运行时使用jupyterlab/yarn.js中的本地yarn版本。如果您决定使用
jlpm命令并遇到jlpm: command not found错误,请尝试将用户级别的 bin 目录添加到您的PATH环境变量中。您已经在之前的命令中随 JupyterLab 一起安装了jlpm,但由于PATH环境变量相关问题,jlpm可能无法访问。如果您使用的是 Unix 派生系统(FreeBSD、GNU/Linux、OS X),您可以使用export PATH="$HOME/.local/bin:$PATH"命令来实现此目的。有时,可能需要使用命令
npm run clean:slate清理您的本地仓库。这将清理仓库,然后重新安装和重建。如果
pip给出VersionConflict错误,这通常意味着已安装的jupyterlab_server版本已过时。运行pip install --upgrade jupyterlab_server以获取最新版本。要在单个 conda/虚拟环境中独立安装 JupyterLab,您可以向上述扩展激活添加
--sys-prefix标志;这会将安装绑定到您的环境的sys.prefix位置,而不会在您的用户范围设置区域(对所有环境可见)中写入任何内容您可以运行
jlpm run build:dev:prod来构建更精确的源映射,以便在调试时显示原始 Typescript 代码。然而,构建源需要更长的时间,因此默认情况下仅用于生产构建。
有关想要编写文档的贡献者的安装说明,请参阅编写文档
运行 JupyterLab#
以开发模式启动 JupyterLab
jupyter lab --dev-mode
开发模式确保您正在运行在开发安装的 Python 包中构建的 JavaScript 资产。请注意,在开发模式下运行时,扩展默认不会激活 - 有关详细信息,请参阅扩展开发文档。
在开发模式下运行时,页面顶部会出现一条红色条纹;这表示正在运行未发布版本。
如果您想修改 TypeScript 代码并实时重建(每次重建后需要刷新页面):
jupyter lab --dev-mode --watch
构建并运行测试#
jlpm run build:testutils
jlpm test
您可以通过更改到相应的包文件夹来运行单个包的测试
cd packages/notebook
jlpm run build:test
jlpm test --runInBand
注意
--runInBand 选项将在当前进程中串行运行所有测试。我们建议使用此选项,因为有些测试会启动一个 Jupyter 服务器,而不喜欢并行执行。
我们使用 jest 进行所有测试,因此标准的 jest 工作流适用。测试可以在 VSCode 或 Chrome 中调试。调试时添加 it.only 到特定测试会有所帮助。每个包中的所有 test* 脚本都接受 jest cli 选项。
VSCode 调试#
要在 VSCode 中调试,请在 VSCode 中打开一个包文件夹。我们在每个包文件夹中提供了一个启动配置。在终端中,运行 jlpm test:debug:watch。在 VSCode 中,从“运行”侧边栏选择“附加到 Jest”以开始调试。有关更多详细信息,请参阅 VSCode 调试文档。
Chrome 调试#
要在 Chrome 中调试,请在终端中运行 jlpm test:debug:watch。打开 Chrome 并转到 chrome://inspect/。选择远程设备并开始调试。
测试工具#
testutils 中有一些辅助函数(这是一个名为 @jupyterlab/testutils 的公共 npm 包),许多测试都使用了这些函数。
对于依赖 @jupyterlab/services(启动内核、与文件交互等)的测试,有两种选择。如果需要简单的交互,testutils 暴露的 Mock 命名空间有许多模拟实现(请参阅 testutils/src/mock.ts)。如果需要完整的服务器交互,请使用 JupyterServer 类。
我们有一个名为 testEmission 的辅助函数,用于帮助编写使用 Lumino 信号的测试,以及一个 framePromise 函数来获取 requestAnimationFrame 的 Promise。我们有时必须在 Promise 内设置一个哨兵值,然后检查哨兵是否已设置,如果我们需要一个 Promise 在不阻塞的情况下运行。
国际化#
可翻译字符串更新#
可翻译字符串的更新不能在补丁版本中进行。它们必须推迟到次要版本或主要版本中。
性能测试#
JupyterLab 的基准测试使用 Playwright 完成。测量的操作包括:
打开文件
从文件切换到简单文本文件
切换回文件
关闭文件
测试了两个文件:一个包含许多代码单元的笔记本和一个包含许多 Markdown 单元的笔记本。
该测试在 CI 上运行,通过比较 PR 分支开始时的提交结果和 PR 分支头部在同一 CI 作业上的结果来确保使用相同的硬件。基准测试作业在以下情况下触发:
已批准的 PR 审查
包含“
please run benchmark”语句的 PR 审查
测试位于 galata/test/benchmark 子文件夹中。它们可以通过以下命令执行:
jlpm run test:benchmark
在 benchmark-results 文件夹中将生成一个特殊报告,其中包含 4 个文件:
lab-benchmark.json:测试的执行时间及一些元数据。lab-benchmark.md:Markdown 格式的报告。lab-benchmark.png:执行时间分布的比较。lab-benchmark.vl.json:用于生成 PNG 文件的 Vega-Lite 描述。
标记为预期的引用存储在 lab-benchmark-expected.json 中。它可以使用 Playwright 的 -u 选项创建;即 jlpm run test:benchmark -u。
基准测试参数#
基准测试可以使用以下环境变量进行自定义
BENCHMARK_NUMBER_SAMPLES:计算执行时间分布的样本数;默认 20。BENCHMARK_OUTPUTFILE:基准测试结果输出文件;默认benchmark.json。它在playwright-benchmark.config.js中被覆盖。BENCHMARK_REFERENCE:数据的引用名称;当前数据默认为actual,引用数据默认为expected。
可以在 JupyterLab 分支上手动执行更多测试,并在 jupyterlab/benchmarks 仓库中的默认分支上每周运行。
视觉回归和 UI 测试#
作为 JupyterLab CI 工作流的一部分,UI 测试会运行视觉回归检查。Galata 用于 UI 测试。Galata 提供了 Playwright 辅助函数,用于以编程方式控制和检查 JupyterLab UI。
UI 测试针对 JupyterLab 项目中的每个提交(PR 或直接提交)运行。代码更改有时可能由于各种原因导致 UI 测试失败。每次测试运行后,Galata 都会生成一份用户友好的测试结果报告,可用于检查失败的 UI 测试。结果报告会显示失败原因、故障发生时的调用堆栈以及视觉回归问题的详细信息。对于视觉回归错误,报告中提供了参考图像和测试捕获图像,以及比较时生成的差异图像。您可以使用这些信息来调试失败的测试。Galata 测试报告可以从 GitHub Actions 页面下载,用于 UI 测试运行。测试工件命名为 galata-report,一旦解压,您可以通过启动服务器来提供文件 python -m http.server -d <path-to-extracted-report> 来访问报告。然后使用您的网络浏览器打开 https://:8000/。
UI 测试失败的主要原因有:
代码更改导致的视觉回归:
有时对项目源代码的修改会引入意想不到的 UI 更改。视觉回归测试的目标是检测此类 UI 更改。如果您的 PR/提交导致视觉回归,则调试并修复由此造成的回归。您可以在本地运行和调试 UI 测试以修复视觉回归。要调试您的测试,您可以运行
PWDEBUG=1 jlpm playwright test <path-to-test-file>。一旦您有了修复,您可以将更改推送到您的 GitHub 分支并通过 GitHub actions 进行测试。用户界面的有意更新:
如果您的代码更改导致 UI 更新,从而导致现有 UI 测试失败,则您需要更新失败测试的参考图像。为此,您可以在 PR 上发布包含以下内容的评论:
please update galata snapshots:机器人将向您的 PR 推送新的提交,更新 galata 测试快照。please update documentation snapshots:机器人将向您的 PR 推送新的提交,更新文档测试快照。please update snapshots:结合前两个评论的效果。
机器人将用 +1 表情符号回应,表示运行已开始,然后在结束后再次评论。由于安全考虑,此功能仅限于一部分拥有更高权限的用户。
有关 UI 测试的更多信息,请阅读 UI 测试开发人员文档和 Playwright 文档。
集成测试的最佳实践#
以下是编写集成测试时应遵循的一些良好实践:
不要在同一个测试中比较多个屏幕截图;如果第一个比较失败,将需要多次运行 CI 工作流来修复所有测试。
贡献调试器前端#
要修改调试器扩展,需要一个支持调试的内核。
请查阅用户文档以了解如何安装此类内核:调试器。
然后刷新页面,调试器侧边栏应出现在右侧区域。
调试器适配器协议#
下图说明了 JupyterLab 扩展和内核之间发送的消息类型。
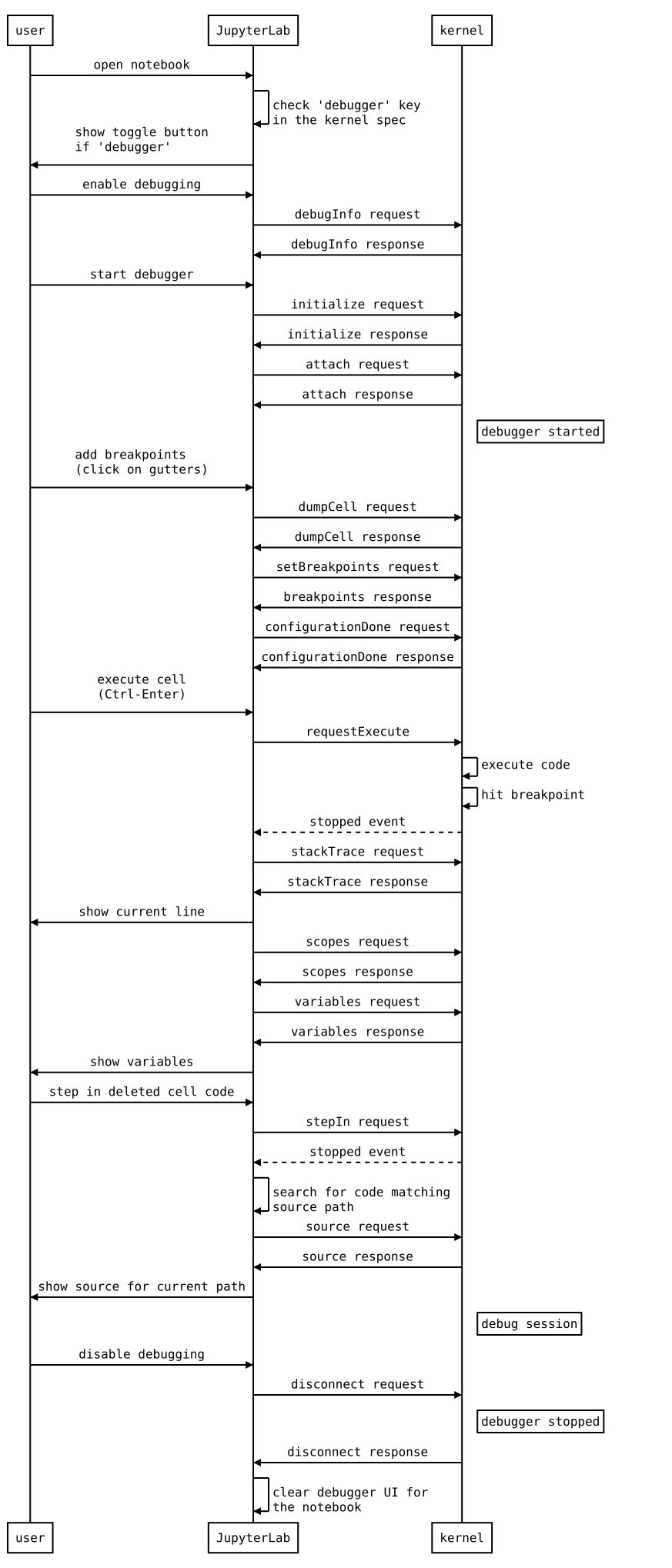
在 VS Code 中检查调试消息#
在 VS Code 中检查调试消息对于了解何时发出调试请求(例如由 UI 操作触发),以及比较 JupyterLab 调试器与 VS Code 中 Python 调试器的行为很有用。
第一步是创建一个测试文件和调试配置(launch.json)。

{
"version": "0.2.0",
"configurations": [
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"env": { "DEBUGPY_LOG_DIR": "/path/to/logs/folder" }
}
]
}
然后启动调试器
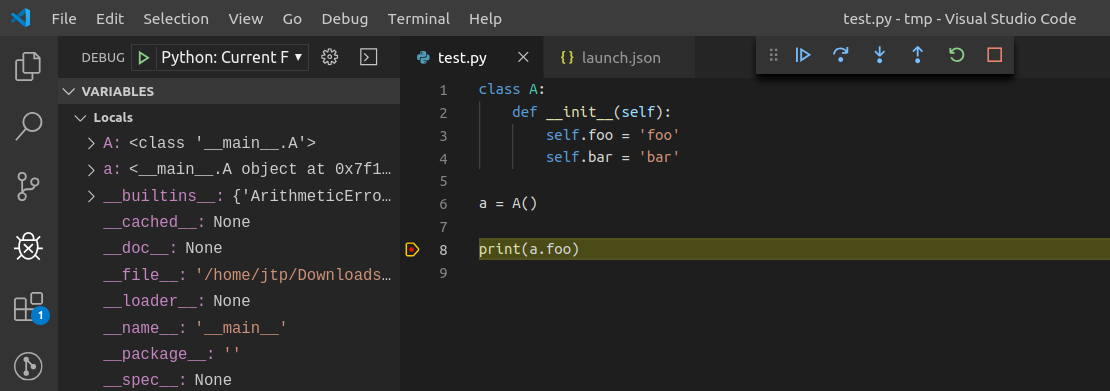
日志文件的内容如下:
...
D00000.032: IDE --> {
"command": "initialize",
"arguments": {
"clientID": "vscode",
"clientName": "Visual Studio Code",
"adapterID": "python",
"pathFormat": "path",
"linesStartAt1": true,
"columnsStartAt1": true,
"supportsVariableType": true,
"supportsVariablePaging": true,
"supportsRunInTerminalRequest": true,
"locale": "en-us"
},
"type": "request",
"seq": 1
}
...
其中
IDE= VS CodePYD= pydev 调试器消息遵循 DAP
参考#
构建并运行独立示例#
要安装和构建 examples 目录中的示例:
jlpm run build:examples
要运行特定示例,请切换到示例目录(例如 examples/filebrowser)并输入
python main.py
在浏览器中调试#
所有构建 JupyterLab 的方法都会生成源映射。源映射应该在浏览器开发工具的源文件视图中 webpack:// 标题下可用。
正常运行 JupyterLab 时,展开 ~ 标题以查看单个包的源映射。
在 --dev-mode 模式下运行时,核心包可在 packages/ 下找到,而第三方库可在 ~ 下找到。注意:建议在调试时使用 jupyter lab --watch --dev-mode。
运行测试时,包将在顶层可用(例如 application/src),而当前测试文件集在 /src 下可用。注意:建议在调试测试选项时在测试文件夹中使用 jlpm run watch。有关详细信息,请参阅上文。
高级架构#
JupyterLab 应用程序由两个主要部分组成:
一个 npm 包
一个 Jupyter 服务器扩展(Python 包)
每个部分都名为 jupyterlab。开发人员教程文档提供了额外的架构信息。
NPM 包#
该仓库由许多 npm 包组成,这些包使用 lerna 构建工具进行管理。npm 包源文件位于 packages/ 子目录中。
从源代码构建 NPM 包#
git clone https://github.com/jupyterlab/jupyterlab.git
cd jupyterlab
pip install -e .
jlpm
jlpm run build:packages
重建
jlpm run clean
jlpm run build:packages
编写文档#
文档以 Markdown 和 reStructuredText 编写。特别是,我们 Read the Docs 页面上的文档是用 reStructuredText 编写的。为了确保 Read the Docs 页面能够构建,您需要使用 pip 安装文档依赖项
pip install -e ".[docs]"
要测试文档,请运行
python -m pytest --check-links -k .md . || python -m pytest --check-links -k .md --lf .
Read the Docs 页面可以使用 make 构建
cd docs
make html
JupyterLab API 参考文档也包含在前面的步骤中。要访问文档,首先启动一个服务器来提供生成的文件:
make serve
然后用您的浏览器访问 https://:8000/。
JupyterLab API 参考文档可以使用 jlpm 单独构建
jlpm run docs
写作风格#
以第二人称撰写文档,称呼读者为“您”。不要使用第一人称复数“我们”。文档的作者不坐在用户旁边,因此使用“我们”可能会在事情不如预期时导致沮丧。
避免使用“简单地”或“仅仅”等轻视 JupyterLab 使用的词语。开发者认为简单或容易的任务对用户来说可能并非如此。
使用主动语态。例如,写“拖动笔记本单元格...”而不是“笔记本单元格可以被拖动...”。
每个部分的开头应以对主题、功能或组件的简短(1-2 句话)高级描述开始。
使用“enable”而非“allow”来表明 JupyterLab 为用户提供了什么可能。使用“allow”暗示我们正在给予他们许可,而“enable”则暗示赋权。
用户界面命名约定#
文档、文件和活动#
根据上下文,将文件称为文件或文档。
文档更以人为中心。如果人工查看、解释或交互是体验的重要组成部分,请使用“文档”一词。例如,笔记本和 Markdown 文件通常被称为文档,除非在文件系统上下文中(例如,笔记本文件名)。
在非以人为中心的上下文中,使用文件一词。例如,在与文件系统或文件名相关的上下文中提及文件。
活动可以是打开的文档,也可以是与文件无关的其他 UI 面板,例如终端、控制台或检查器。
笔记本单元格#
一个笔记本包含单元格,每个单元格都有输入和一个或多个输出。当用户运行一个单元格时,内核读取并执行输入并生成输出。然后笔记本显示该单元格的输出。术语输出描述了运行一个单元格可能产生的多个结果中的一个。单元格输出描述了一个单元格的全部输出。使用所有单元格的输出来描述所有单元格的所有输出。
命令名称#
命令名称出现在菜单、命令面板和工具栏按钮中(名称通常在悬停时显示)。
保持命令名称简短、简洁、明确。
在任何需要更多选项的命令名称后添加省略号 (…) 。这告诉用户,在执行命令之前,他们应该会看到一个弹出窗口。
命令应使用祈使语态的动词。不要在名词前使用冠词。例如,写“Clear Cell”(清除单元格),而不是“Clear the Cell”(清除该单元格)或“Clearing Cell”(正在清除单元格)。
元素名称#
选项卡式 UI 的通用内容区域是面板。通过其最具体的名称来指代面板,例如“文件浏览器”。选项卡栏有选项卡,用户可以通过它们查看不同的面板。
菜单栏包含有其自己的子菜单的菜单项。
当名称明确时,将主工作区称为工作区。
描述 UI 中的元素时,首选口语化名称而非技术名称。例如,使用“文件浏览器”而不是“文件面板”。
大多数元素名称采用小写。这些名称包括:
选项卡
面板
菜单栏
侧边栏
文件
文档
活动
选项卡栏
主工作区
文件浏览器
命令面板
单元格检查器
代码控制台
用户界面的以下部分首字母或多个单词的首字母大写,以反映它们在 UI 中的用法:
活动栏
文件菜单
文件选项卡
运行面板
选项卡面板
简单界面模式
有关 UI 中元素的描述,请参阅JupyterLab 界面。
Jupyter 服务器扩展#
Jupyter 服务器扩展源代码位于 jupyterlab/ 子目录中。要使用此扩展,请确保已安装 Jupyter Notebook 服务器版本 4.3 或更高版本。
构建 JupyterLab 服务器扩展#
当您修改 JupyterLab npm 包源文件时,运行
jlpm run build
来构建更改,然后刷新浏览器以查看更改。
要使系统在每次源文件更改后自动构建,请运行
jupyter lab --dev-mode --watch
构建工具#
有多种构建工具用于维护仓库。要获取库的建议版本,请使用 jlpm run get:dependency foo。要在整个仓库中更新库的版本,请使用 jlpm run update:dependency foo ^latest。要删除不需要的依赖项,请使用 jlpm run remove:dependency foo。
关键工具是 jlpm run integrity,它确保仓库中包的完整性。它将:
确保核心包版本依赖关系在所有地方都匹配。
确保导入的包与依赖关系匹配。
确保所有包的版本一致。
管理元包。
packages/metapackage 包用于一次性构建仓库中的所有 TypeScript,而不是进行 50 多个单独的构建。
完整性脚本还允许您通过从 TypeScript 文件中导入,然后从仓库根目录运行 jlpm run integrity,从而自动为包添加依赖项。
我们还提供了在 packages/ 中创建和删除包的脚本:jlpm run create:package 和 jlpm run remove:package。创建包时,如果它打算包含在核心捆绑包中,请将 jupyterlab: { coreDependency: true } 元数据添加到 package.json。带有 extension 或 mimeExtension 元数据的包被认为是核心依赖项,除非它们被明确标记为非核心依赖项。
测试对外部包的更改#
链接/取消链接包到 JupyterLab#
如果您想更改 JupyterLab 的外部包(例如 Lumino)并针对您的 JupyterLab 副本进行测试,您可以使用 link 命令轻松实现
进行更改,然后构建外部包
将 JupyterLab 链接到修改后的包
导航到您的 JupyterLab 仓库的顶层,然后运行
jlpm link <path-to-external-repo> --all
3. 然后您可以(重新)构建 JupyterLab(例如 jlpm run build),您的更改应该会被构建过程识别。
要将 JupyterLab 恢复到其原始状态,您可以使用 unlink 命令
解除 JupyterLab 和修改后的包的链接
导航到您的 JupyterLab 仓库顶层,然后运行
jlpm unlink <path-to-external-repo> --all
在 JupyterLab 中重新安装外部包的原始版本
运行
jlpm install --check-files
3. 然后您可以(重新)构建 JupyterLab,所有内容都应该恢复为默认值。
可能的链接陷阱#
如果您正在处理一个包含多个包的外部项目,您可能需要链接项目中所有包的副本,包括那些您没有进行任何更改的包。未能这样做可能会导致与共享状态重复相关的问题。
具体来说,在使用 Lumino 时,您可能需要链接 "@lumino/messaging" 包的副本(除了您实际更改的任何包之外)。这可能是由于 messaging 包提供的 MessageLoop 命名空间中包含的对象可能重复。
键盘快捷键#
键盘快捷键排版如下:
等宽字体,单个键之间有空格:
Shift Enter。对于修饰键,使用平台无关的描述键的单词:
Shift。对于
Accel键,使用短语:Command/Ctrl。不要使用平台特定的修饰键图标,因为它们在 Sphinx/RTD 上难以以平台特定的方式显示。
屏幕截图和动画#
我们的文档应该包含截图和动画,以说明和演示软件。以下是准备它们的一些指南:
确保截图不包含受版权保护的材料(首选),或许可在我们的文档中允许并明确说明。
对于屏幕截图,您应该首选创建视觉测试。这允许动态更新它们。这些测试在
galata/test/documentation文件夹中定义。如果截取 PNG 屏幕截图,请使用 Firefox 或 Chrome 开发工具执行以下操作:
将浏览器视口设置为 1280x720 像素
将设备像素比设置为 1:1(即非 hidpi,非 retina)
使用浏览器开发工具截取整个视口。屏幕截图不应包含任何浏览器元素,例如浏览器地址栏、浏览器标题栏等,也不应包含任何桌面背景。
如果创建电影,请按上述设置调整(1280x720 视口分辨率,非 hidpi),并使用您选择的屏幕捕获实用程序仅捕获浏览器视口。
对于 PNG 文件,使用
pngquant --speed 1 <filename>缩小其大小。生成的文件名将附加-fs8,因此请务必重命名并使用生成的文件。将优化后的 PNG 文件提交到主仓库。每个 PNG 文件应不超过几百千字节。对于电影,将其上传到 IPython/Jupyter YouTube 频道,并将其添加到 jupyterlab-media 仓库。要在文档中嵌入电影,请使用
www.youtube-nocookie.com网站,该网站可以通过点击 YouTube 分享对话框中的“隐私增强”嵌入选项找到。在 URL 末尾添加以下参数?rel=0&showinfo=0。这会禁用视频标题和相关视频建议。屏幕截图或动画应在其前面加上一句描述内容的句子,例如“要打开文件,请在文件浏览器中双击其名称:”。
我们有自定义 CSS,可以为屏幕截图和嵌入式 YouTube 视频添加阴影和适当的大小。请参阅文档中的示例,了解如何嵌入这些资产。
为了帮助我们组织屏幕截图和动画,请使用与它们所使用的源文件名匹配的前缀来命名文件:
sourcefile.rst sourcefile_filebrowser.png sourcefile_editmenu.png
这将有助于我们随着文档内容的演变跟踪图像。
注意事项#
默认情况下,应用程序将从 JupyterLab 暂存目录加载(默认为
<sys-prefix>/share/jupyter/lab/build)。如果您希望在<git root>/jupyterlab/build中运行核心应用程序,请运行jupyter lab --core-mode。这是将要发布的核心应用程序。如果使用扩展,请参阅扩展文档。
npm 模块与 Node/Babel/ES6/ES5 完全兼容。在使用 TypeScript 以外的语言时,只需省略类型声明。